Disclaimer: Clicking on source code linked to in this page will link to offensive words and text
Recently I competed in a Kaggle / Google Jigsaw Toxic Comment Classification Contest which ended in early March. The challenge was to classify comments as being normal or as being in one or more toxic categories. Some of the classes had large class imbalances and shown by the following graph.
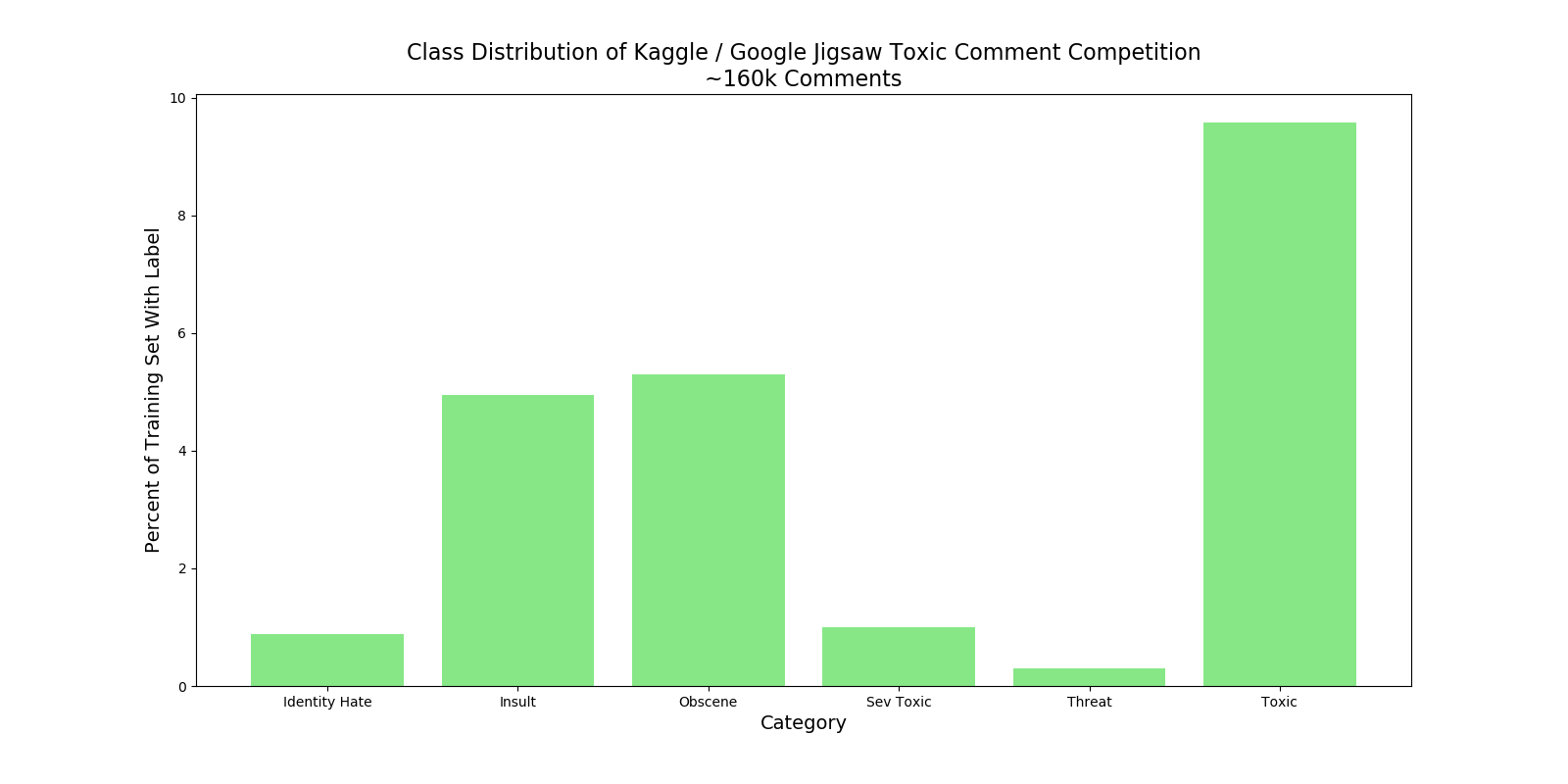
Initially I performed Eploratory Data Analysis (EDA) looking at the class distributions as well as most common word frequencies per class. Then I started looking at the comments themselves, of different types of classes, and started looking for patterns. Especially patterns that I did not think would survive the normal word vectorization process. The main intuition was to look for features that could be concatenated late in the RNN that would be used to make predictions, providing a bit more signal for the network’s decision boundaries.
Sentence Structure Features:
“Words per Comment”
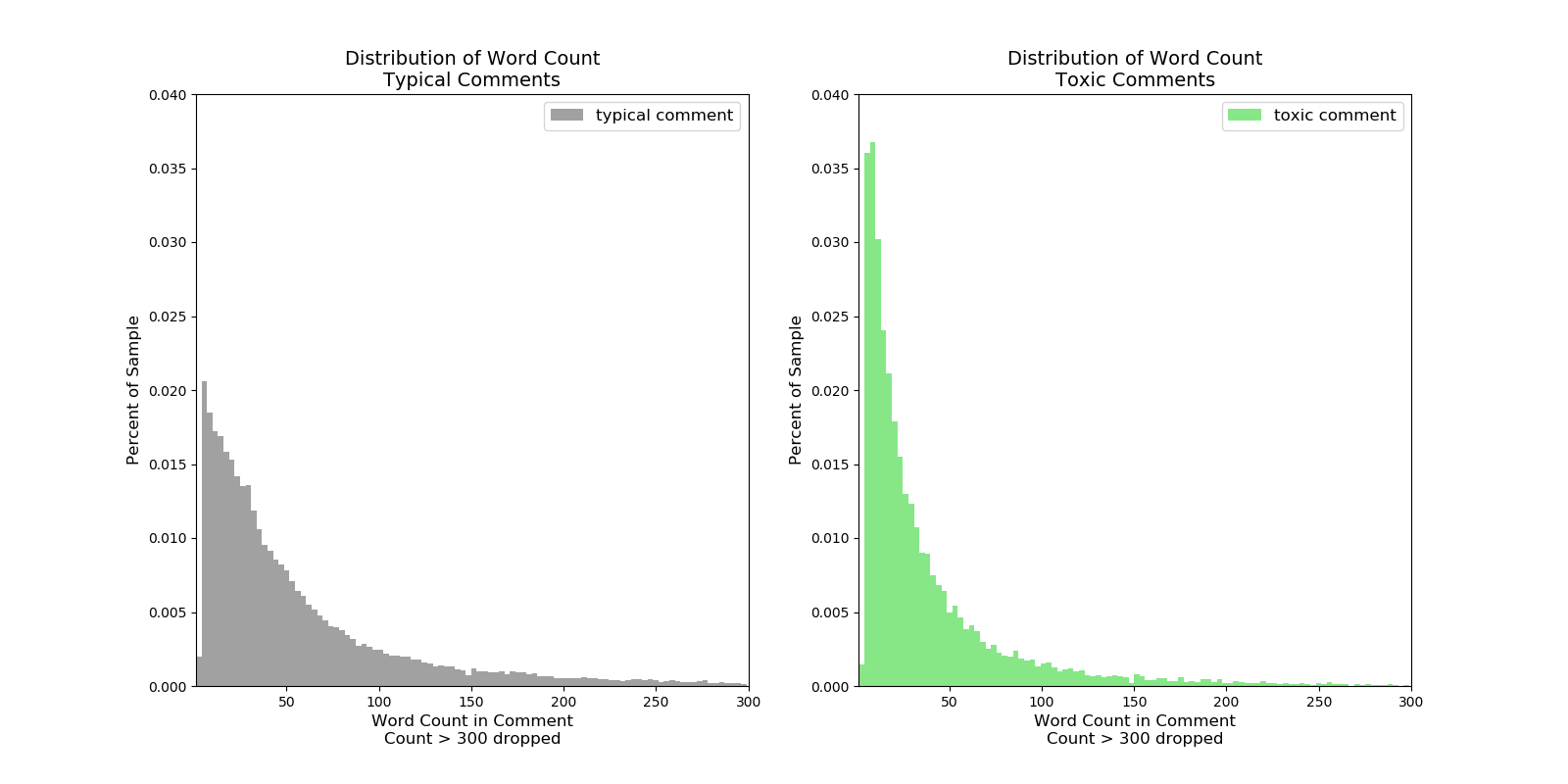
Words per Comment: One of the most basic things to look at was to see if there was a difference in length between toxic comments and normal comments. Because it’s an exponential distribution a log transformation was also evaluated also.
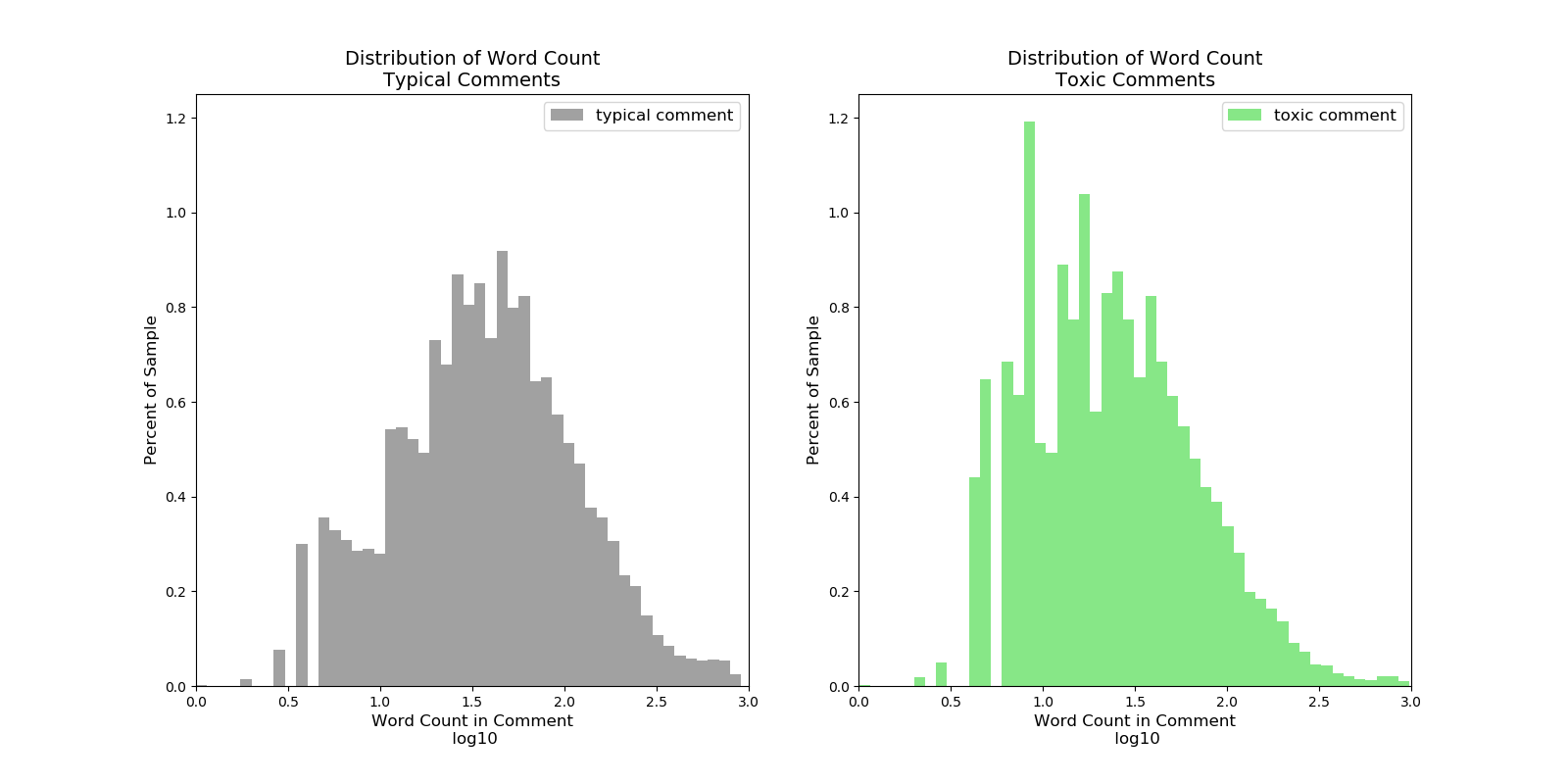
Log10 Words per Comment: The sawtooth patterns on the left sides of the plots is due to integer values having a log transformation applied.
“Repetition”
Anecdotally toxic comments sometimes had some extreme data in which a certain comment was copy and pasted hundreds of times until the message buffer was maxed out. Initially I discovered this during data pipeline related operations and initial EDA with term frequency. Namely because oddly spelled words would end up being in the top 10 non-stop words of a toxic class. One of those examples was “mothjer” which is covered nicely by a fellow Kaggler here warning: offensive words
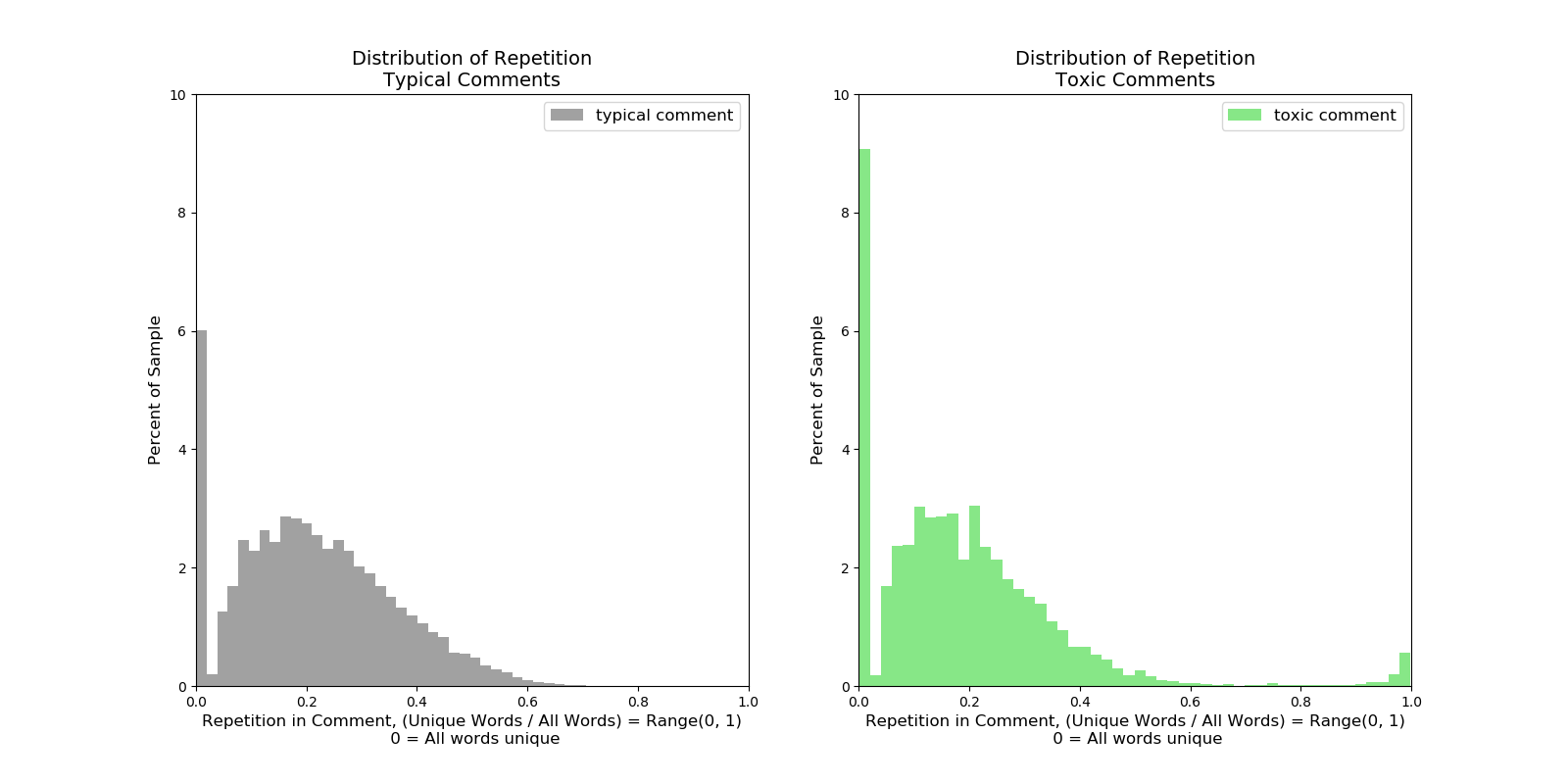
Formula is: 1 - (# of unique words / # of all words) 0 is the value of comments that are totally unique, near 1 would be totally repetitive. The zero values distort the plot so those are dropped in the next plot. There is a decent bump in uniqueness for toxic comments.
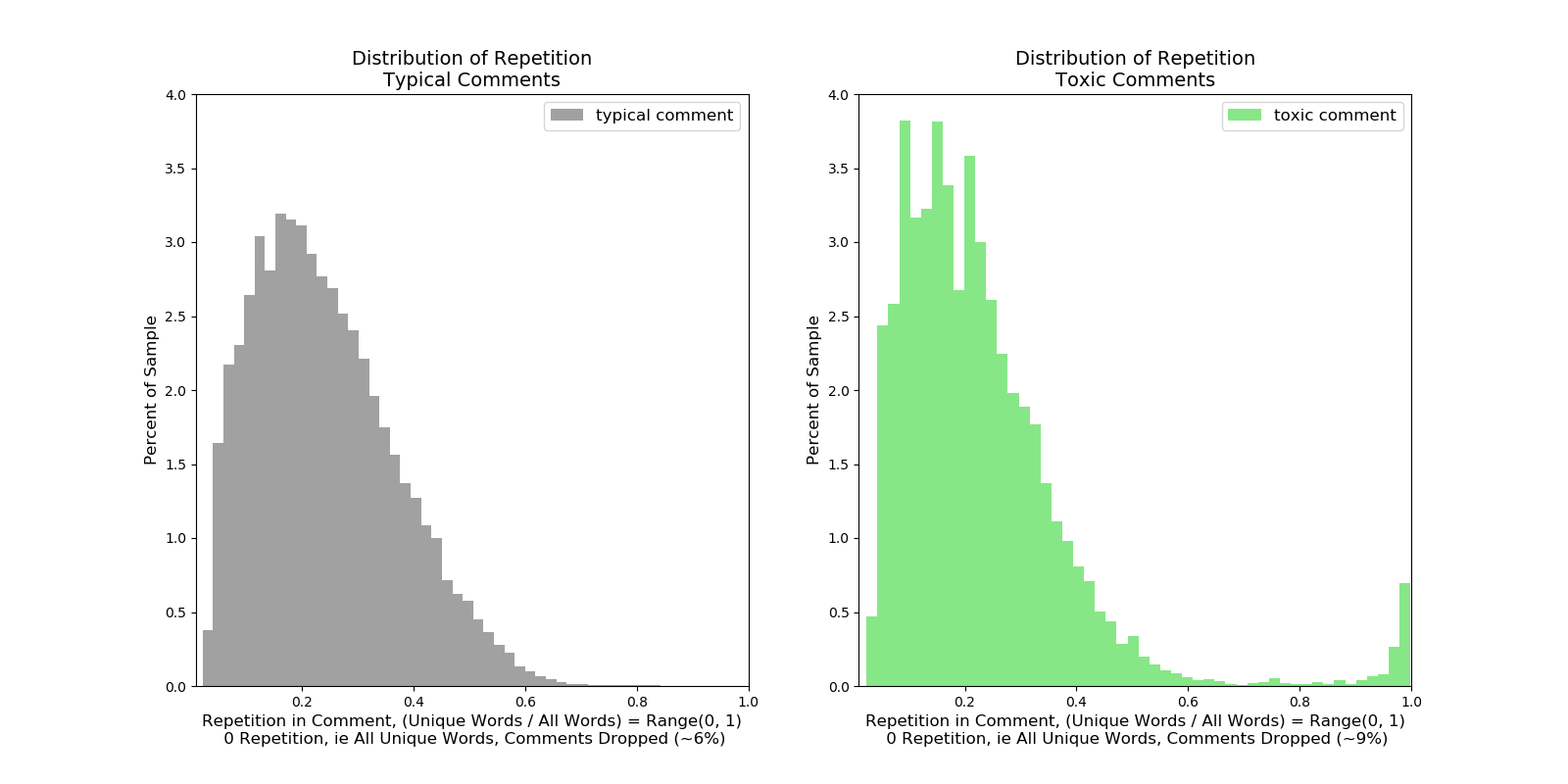
There is also a good bump for toxic comments, indicating that some are very repetitive, on the right side of the plot which is distinctly missing from the normal comments.
“Loudness”
Going through and exploring the toxic comments I noticed that a lot of the toxic comments seemed to have more CAPS than usual. Given that is internet ‘yelling’ it makes sense as toxic messages seemed to be more emotionally charged.
I made a function that counted the proportion of characters that were capitals relative to the total amount of ascii characters. Think (# A-Z / # a-zA-Z) + ε Because a log transformation was going to be needed again a small epsilon was added so that the log operation was never performed on a 0 value. Therefore the spike at about -5.25 are the comments that are all lower case, ie: 0.0 + ε
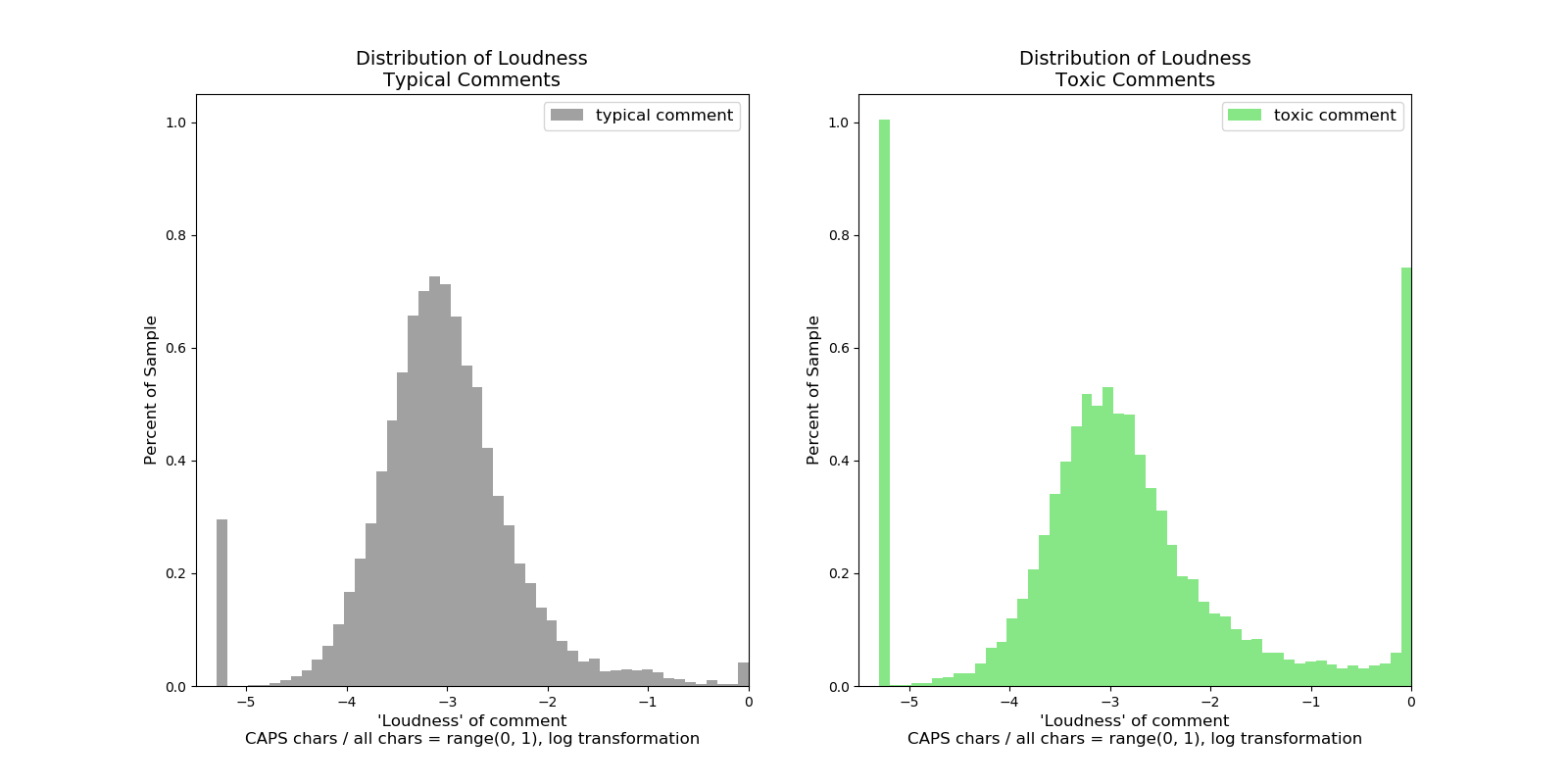
Both have characteristic spikes in all lower and ALL CAPS but the effect is expressed quite a bit more on the toxic comments. This implies that toxic comments are also lower case much more frequently than regular comments.
Punctuation Based Features:
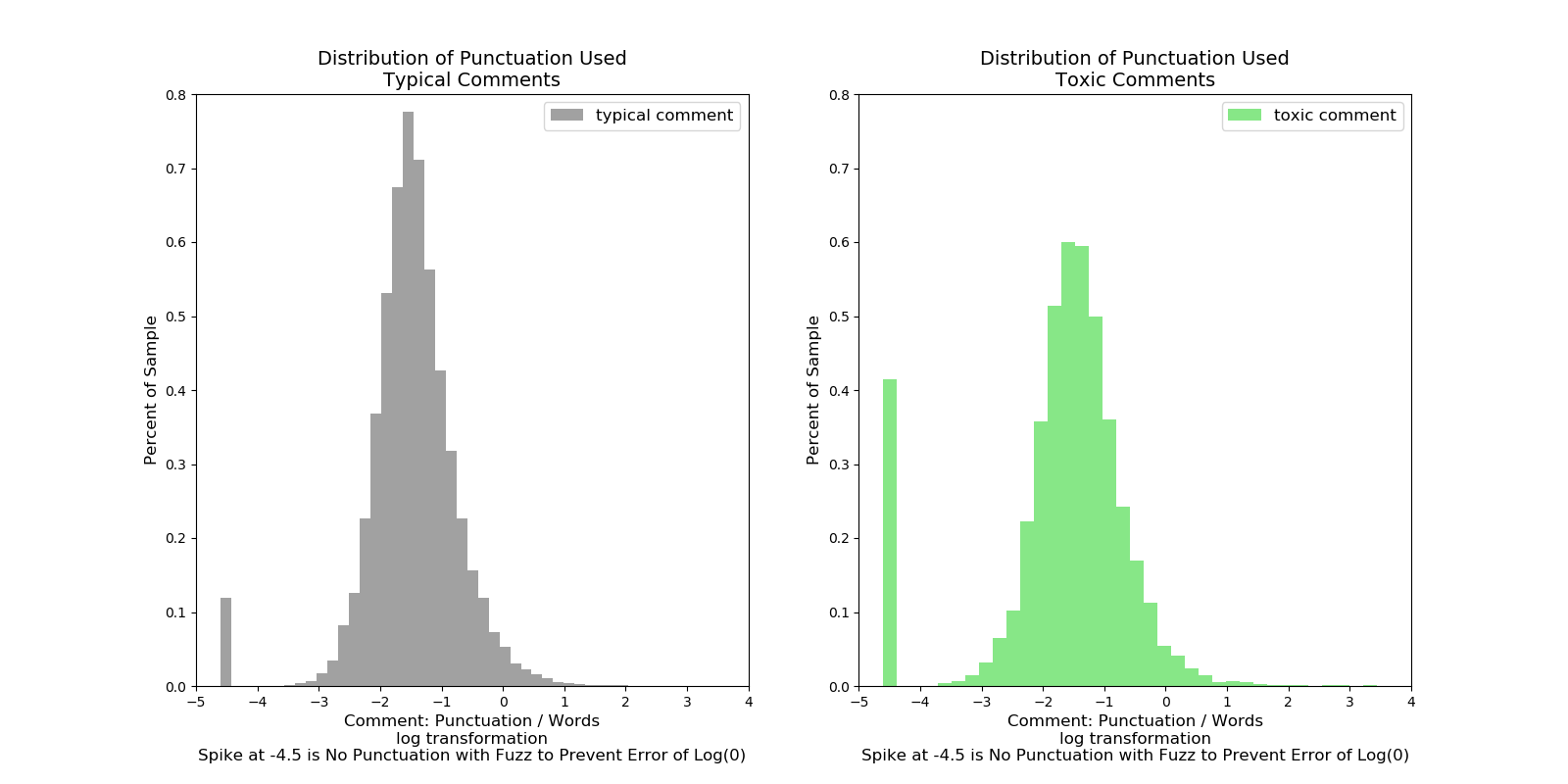
“Punctuation Utilization”
How do typical comments compare with toxic comments as far as amounts of punctuation (python string.punctuation) per word in a comment.
“Urgency”
Very similar to loudness, toxic comments seemed to have many more explanation points.
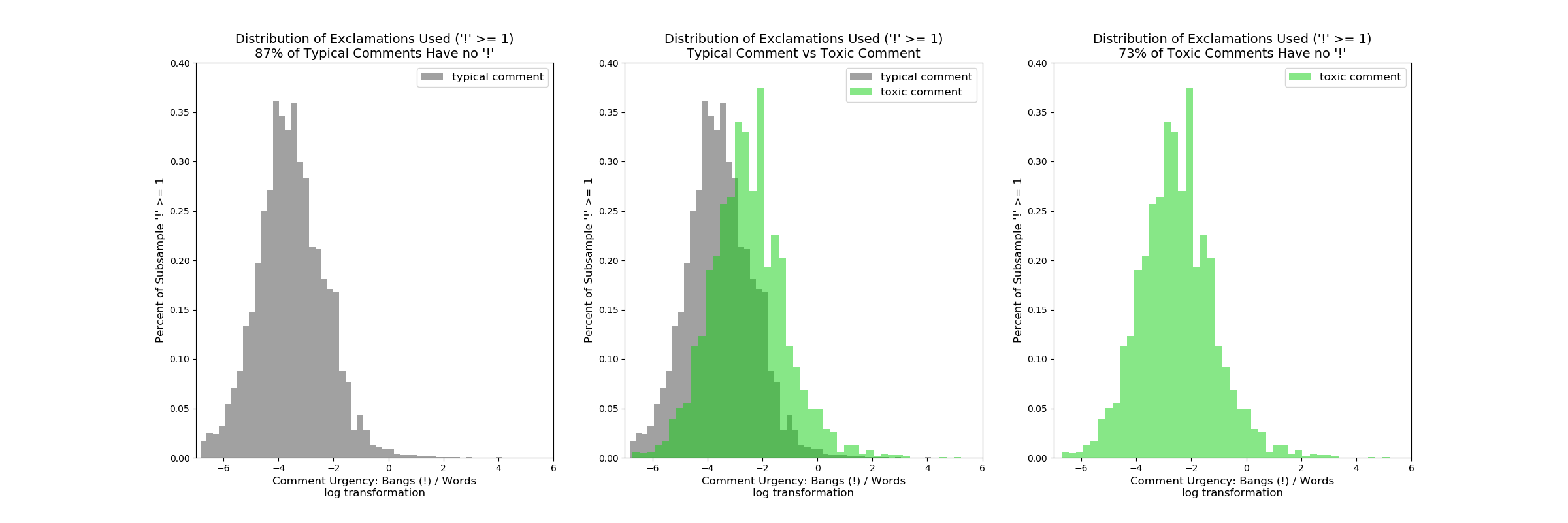
Distribution of Urgency in Comments: 13% of regular comments had an exclamation mark “!” but 27% of toxic comments had at least one “!”. The plot above has exluded counts of 0 as that makes up the majority of both classes. One can clearly see that the toxic comments are right shifted (more “!”s per comment) relative to normal comments.
“Questioning”
Do toxic comments have more or less “?” than normal comments, typically?
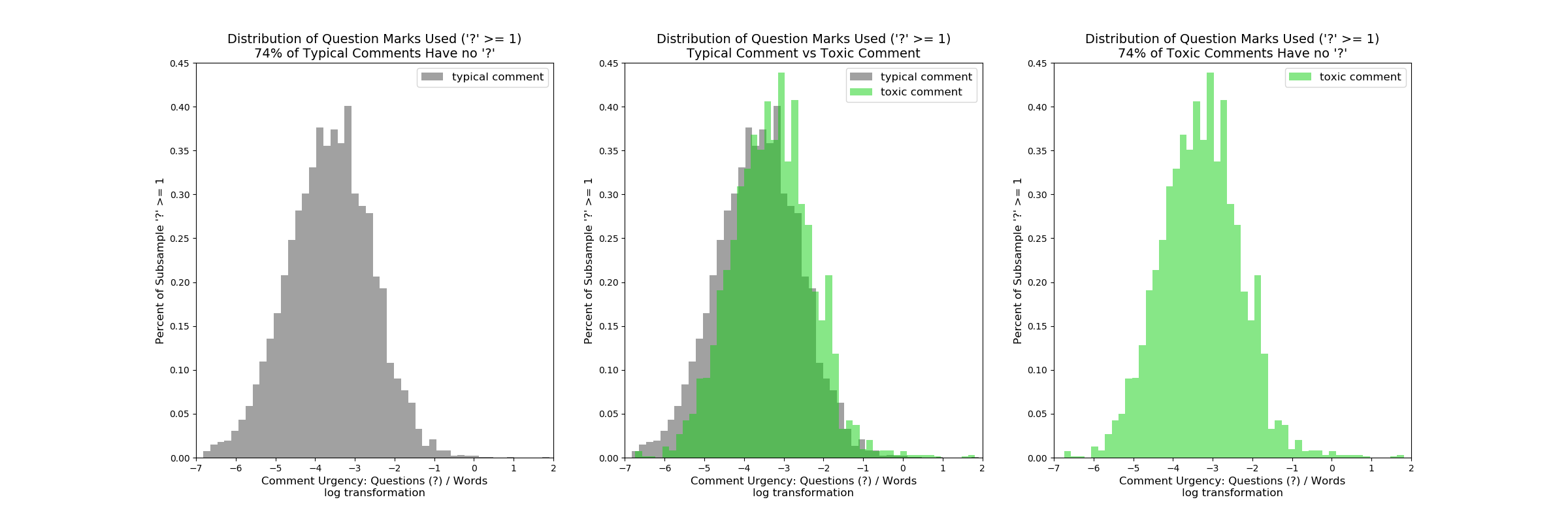
Distribution of Questioning in Comments: 26% of regular comments have a question mark and 26% of toxic comments have question marks. Overlaying the two plots with the same scale there is a slight right shift of toxic comments but the effect is not pronounced.
“Dots”
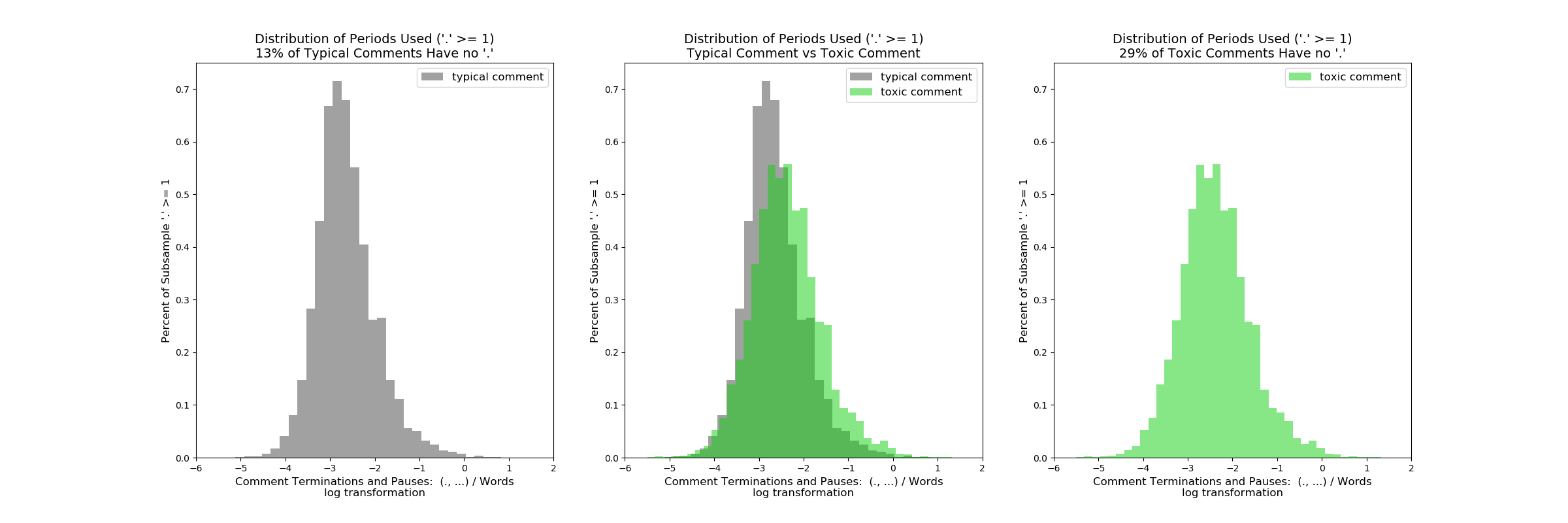
Do toxic comments have more or less “.” or “…” than normal comments, typically? A logical if mundane progression of the statistical punctuation line of thought.